前言
目前最流行的两大前端框架,React和Vue,都不约而同的借助Virtual DOM技术提高页面的渲染效率。那么,什么是Virtual DOM?它是通过什么方式去提升页面渲染效率的呢?
什么是Virtual DOM
本质上来说,Virtual DOM只是一个简单的JS对象,并且最少包含tag、props和children三个属性。不同的框架对这三个属性的命名会有点差别,但表达的意思是一致的。它们分别是标签名(tag)、属性(props)和子元素对象(children)。下面是一个典型的Virtual DOM对象例子
{
tag: "div",
props: {},
children: [
"Hello World",
{
tag: "ul",
props: {},
children: [{
tag: "li",
props: {
id: 1,
class: "li-1"
},
children: ["第", 1]
}]
}
]
}Virtual DOM跟dom对象有一一对应的关系,上面的Virtual DOM是由以下的HTML生成的
<div>
Hello World
<ul>
<li id="1" class="li-1">
第1
</li>
</ul>
</div>一个dom对象,比如li,由tag(li), props({id: 1, class: "li-1"})和children(["第", 1])三个属性来描述。
前端技术框架发展
菜鸟的日常操作
假如现在你需要写一个像下面一样的表格的应用程序,这个表格可以根据不同的字段进行升序或者降序的展示。
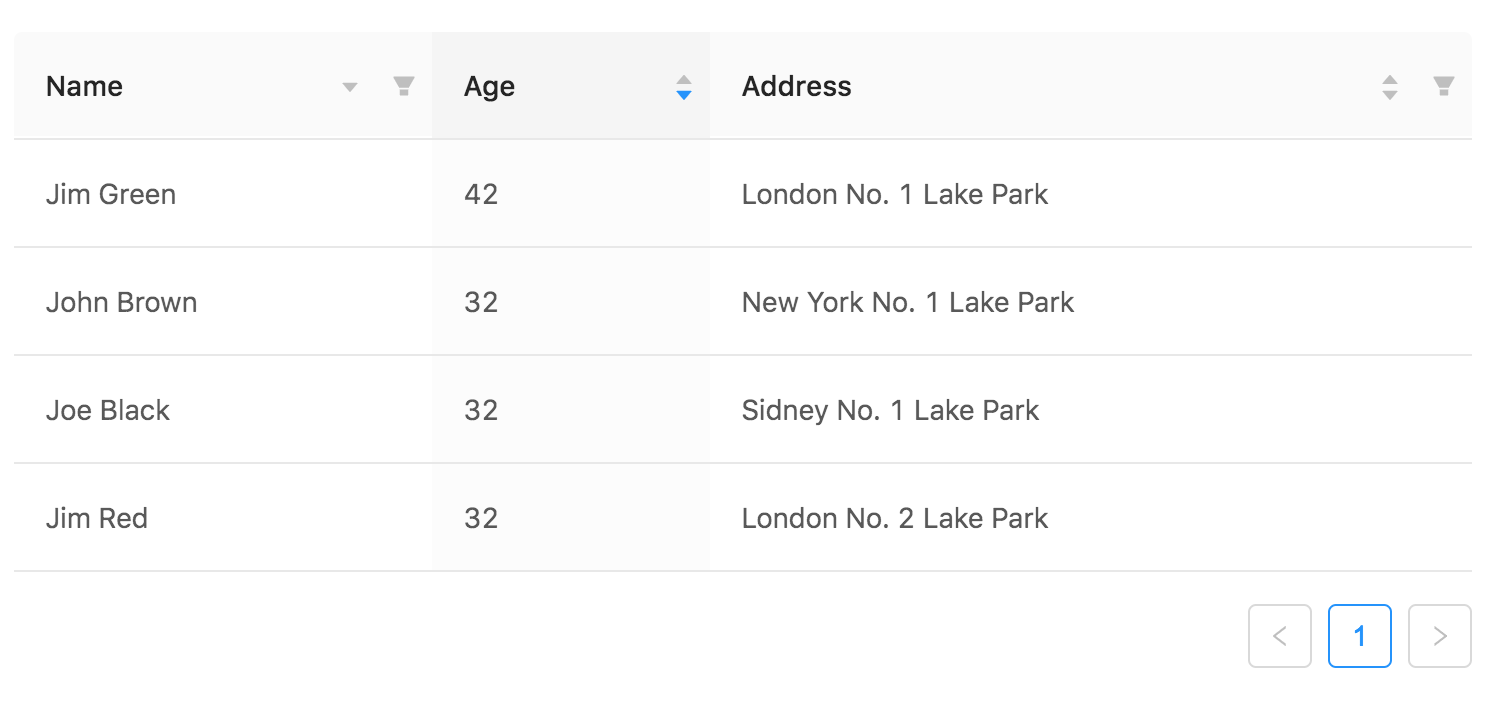
这个应用程序看起来很简单,你可以想出好几种不同的方式来写。最容易想到的可能是,在你的 JavaScript 代码里面存储这样的数据:
var sortKey = "name" // 排序的字段,名字(name)、年龄(age)、地址(address)
var sortType = 1 // 升序还是逆序
var data = [{...}, {...}, {..}, ..] // 表格数据用三个变量分别存储当前排序的字段、排序方向、还有表格数据;
然后给表格头部加点击事件,当用户点击排序字段时,会根据上面几个变量存储的值来对内容进行排序;
然后用 JS 操作 DOM,更新页面的排序状态和表格内容。
这样做的后果是?
随着应用程序越来越复杂,需要在JS里面维护的字段也越来越多,需要监听事件和在事件回调用更新页面的DOM操作也越来越多,应用程序会变得非常难维护。
寻求突破变更?
后来大牛们使用了 MVC、MVP 的架构模式,希望能从代码组织方式来降低维护这种复杂应用程序的难度;但是 MVC 架构没办法减少你所维护的状态,也没有降低状态更新你需要对页面的更新操作(前端来说就是DOM操作),你需要操作的DOM还是需要操作(他大舅他二舅都是他舅),只是换了个地方。
思想的革命、技术的突破
既然前辈大牛们已经实现了状态改变DOM,为什么我们不近一步,做出那么一个东西可以让视图和状态进行
绑定?
让状态变更视图自动跟着变更,就不用手动更新页面了。
这就是后来的 MVVM模式
只要在模版中声明视图组件是和什么状态进行绑定的,双向绑定引擎就会在状态
更新的时候自动更新视图,MVVM 可以能很好的降低维护状态以及减少视图的复杂程度
思维的发散、Virtual DOM的诞生
还有一个非常直观的方法,可以大大降低视图更新的操作。一旦状
态发生了变化,就用模版引擎重新渲染整个视图,然后用新的视图更换掉旧的视图。就
像上面的表格,当用户点击的时,还是在 JS 里面更新状态,但是页面更新就不用手动
操作 DOM 了,直接把整个表格用模版引擎重新渲染一遍,然后设置一下 innerHTML 。
那么这个方法会有个很大的问题,会导致 DOM 操作变慢,因为任何的状态变更都要重
新构造整个 DOM,性价比很低。对于局部的小视图的更新,这样没有问题(backbone
就是这么干的)。但对于大型视图,需要更新页面较多局部视图时,这样的做法就非常不
可取。
Virtual DOM 也是这么做的,只是加了一些步骤来避免了整棵 DOM 树变更。上面提供
的几种方法,其实都在解决同一个问题,那就是维护状态更新视图。如果我们能够很好来
应对这个问题,就降低复杂性。
Virtual DOM 算法
DOM解析流程
DOM 很慢,为啥说它慢,先看一下 Webkit 引擎,所有浏览器都遵循类似的工作流,只
是在细节处理有些不同。
一旦浏览器接收到一个 HTML 文件,渲染引擎 Render Engine就开始解析它,根据 HTML 元素 Elements 对应地生成 DOM 节点 Nodes,最终组成一棵 DOM 树。
构造了渲染树以后,浏览器引擎开始着手布局 Layout。
布局时,渲染树上的每个节点根据其在屏幕上应该出现的精确位置,分配一组屏幕坐标值。
接着,浏览器将会通过遍历渲染树,调用每个节点的 Paint 方法来绘制这些 Render 对象。
Paint 方法根据浏览器平台,使用不同的 UI后端 API(Agnostic UI Backend API)通过绘制,最终将在屏幕上展示内容。
渲染流程图如下:
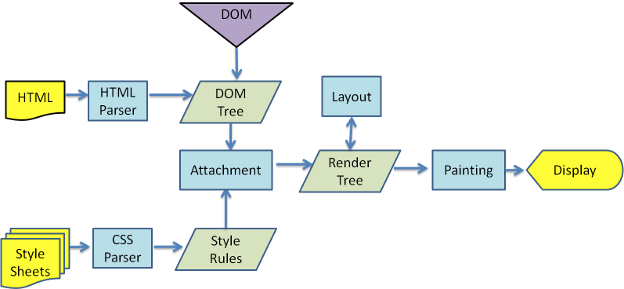
那么问题来了
只要在这过程中进行一次 DOM 更新,整个渲染流程都会重做一遍。
div的属性包含以下这些
align, onwaiting, onvolumechange, ontimeupdate, onsuspend, onsubmit,
onstalled, onshow, onselect, onseeking, onseeked, onscroll, onresize,
onreset, onratechange, onprogress, onplaying, onplay, onpause,
onmousewheel, onmouseup, onmouseover, onmouseout, onmousemove,
onmouseleave, onmouseenter, onmousedown, onloadstart,
onloadedmetadata, onloadeddata, onload, onkeyup, onkeypress,
onkeydown, oninvalid, oninput, onfocus, onerror, onended, onemptied,
ondurationchange, ondrop, ondragstart, ondragover, ondragleave,
ondragenter, ondragend, ondrag, ondblclick, oncuechange,
oncontextmenu, onclose, onclick, onchange, oncanplaythrough,
oncanplay, oncancel, onblur, onabort, spellcheck, isContentEditable,
contentEditable, outerText, innerText, accessKey, hidden,
webkitdropzone, draggable, tabIndex, dir, translate, lang, title,
childElementCount, lastElementChild, firstElementChild, children,
nextElementSibling, previousElementSibling, onwheel,
onwebkitfullscreenerror, onwebkitfullscreenchange, onselectstart,
onsearch, onpaste, oncut, oncopy, onbeforepaste, onbeforecut,
onbeforecopy, webkitShadowRoot, dataset, classList, className,
outerHTML, innerHTML, scrollHeight, scrollWidth, scrollTop,
scrollLeft, clientHeight, clientWidth, clientTop, clientLeft,
offsetParent, offsetHeight, offsetWidth, offsetTop, offsetLeft,
localName, prefix, namespaceURI, id, style, attributes, tagName,
parentElement, textContent, baseURI, ownerDocument, nextSibling,
previousSibling, lastChild, firstChild, childNodes, parentNode,
nodeType, nodeValue, nodeName来看看空的 div 元素有多少属性要实现,这还只是第一层的自有属性,没包括原型链继承而来
的。如果触发了页面事件,就就会导致页面重排。相对于 DOM 对象,原生的 JavaScript 处理
起来才会更快且更简单。
DOM树
DOM 树上的结构、属性信息我们都可以很容易地用 JavaScript 对象表示出来。
var olE = {
tagName: 'ol', // 标签名
props: { // 属性用对象存储键值对
id: 'ol-list'
},
children: [ // 子节点
{tagName: 'li', props: {class: 'item'}, children: ["Item 1"]},
{tagName: 'li', props: {class: 'item'}, children: ["Item 2"]},
{tagName: 'li', props: {class: 'item'}, children: ["Item 3"]},
]
}对应HTML
<ol id='ol-list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ol>虚拟DOM算法的原理
DOM 我们都可以用 JavaScript 对象来表示。那反过来,就可以用 JavaScript 对象表示的树结
构来构建一个真正的 DOM 。当状态变更时,重新渲染这个 JavaScript 的对象结构,实现视图
的变更,结构根据变更的地方重新渲染。
这就是所谓的 Virtual DOM 算法:
- 用 JavaScript 对象结构表示 DOM 树的结构;
- 然后用这个树构建一个真正的 DOM 树
- 插到文档当中当状态变更时,重新构造一棵新的对象树。
- 然后用新的树和旧的树进行比较两个数的差异。
- 然后把差异更新到久的树上,整个视图就更新了。
Virtual DOM 本质就是在 JS 和 DOM 之间做了一个缓存。既然已经知道 DOM 慢,就在 JS 和 DOM 之间加个缓存。JS 先操作 Virtual DOM对比排序/变更,最后再把整个变更写入真实 DOM。
Virtual DOM实现
用JS对象模拟DOM树
用 JavaScript 来表示一个 DOM 节点是很简单的事情,你只需要记录它的节点类型、属性,还有子节点:
export default Ele = (tagName, props, children) => {
this.tagName = tagName
this.props = props
this.children = children
}例如上面的 DOM 结构就可以简单的表示:
import * as el from 'Ele';
var ol = el('ol', {id: 'ol-list'}, [
el('li', {class: 'item'}, ['Item 1']),
el('li', {class: 'item'}, ['Item 2']),
el('li', {class: 'item'}, ['Item 3'])
]);
现在 ol 只是一个 JavaScript 对象表示的 DOM 结构,但页面上并没有这个结构。我们可以根据这
个 ol 构建来生成真正的 ol。新增一个 render 方法,根据 tagName 构建一个真正的 DOM,然
后生成 DOM 属性、连接子结构等等。
Ele.prototype.render = function () {
var e = document.createElement(this.tagName); // 创建元素
var props = this.props;
for (var propName in props) { // 设置 DOM 属性
var propValue = props[propName];
e.setAttribute(propName, propValue);
}
var children = this.children || [];
children.forEach(function (child) {
var childE = (child instanceof Element)
? child.render() // 子节点也是虚拟 DOM,递归构建
: document.createTextNode(child); // 字符串,构建文本节点
e.appendChild(childE);
});
return e;
}最后只需要 render。
var olE = Ele.render()
document.body.appendChild(olE);上面的 olE 是真正的 DOM 节点,把它 append 到 body 中,这样就有了真正的 ol DOM 元素。
<ol id='ol-list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ol>Virtual DOM 树的差异介绍(Diff算法)
比较两棵虚拟DOM树的差异
正如你所预料的,比较两棵DOM树的差异是 Virtual DOM 算法最核心的部分,这也是所谓的 Virtual DOM 的 diff 算法。两个树的完全的 diff 算法是一个时间复杂度为 O(n^3) 的问题。但是在前端当中,你很少会跨越层级地移动DOM元素。所以 Virtual DOM 只会对同一个层级的元素进行对比:
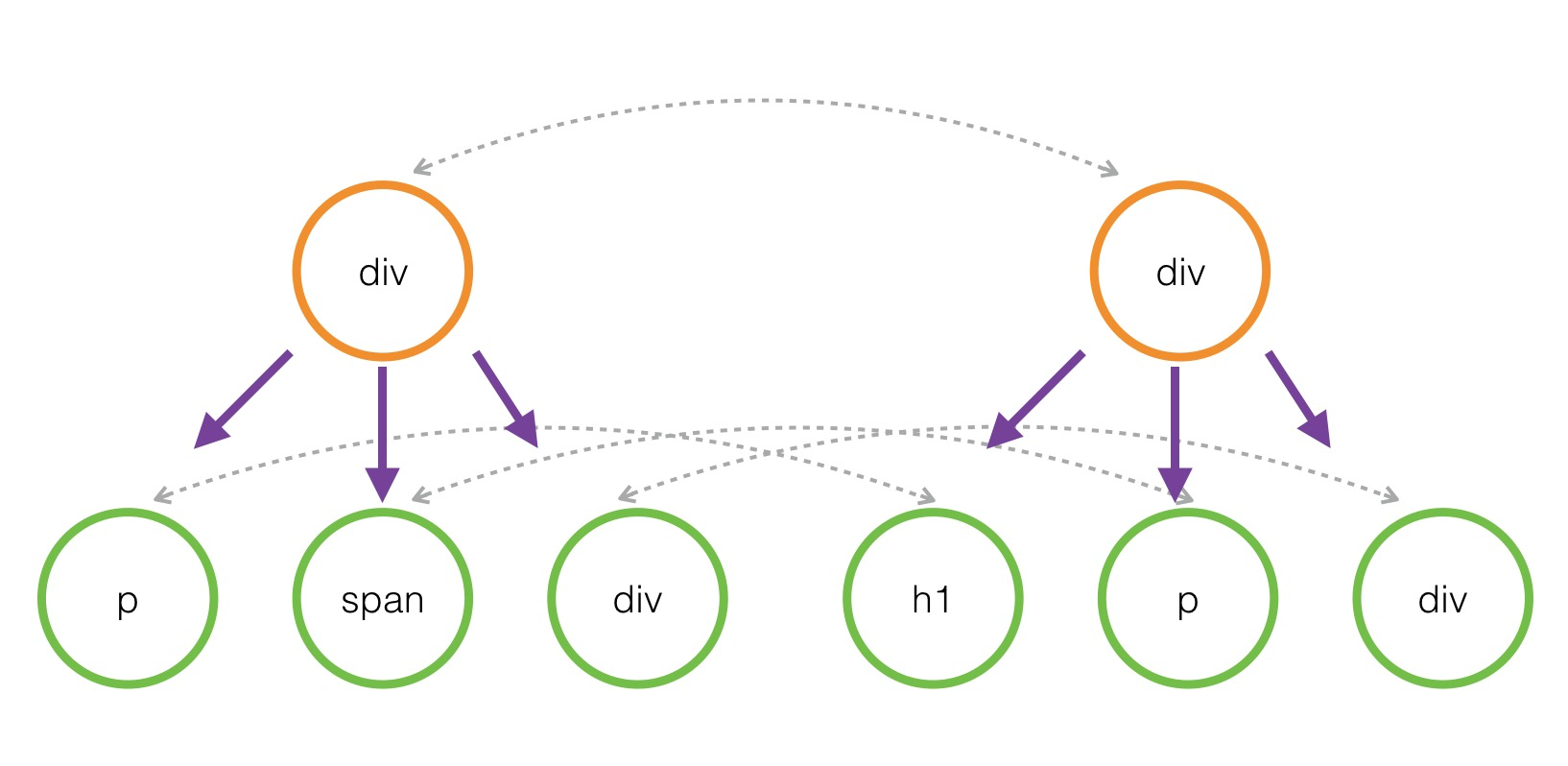
上面的div只会和同一层级的div对比,第二层级的只会跟第二层级对比。这样算法复杂度就可以达到 O(n)。
差异是指的是什么呢?DOM 替换掉原来的节点,如把上面的 div 换成了 section 进行移动、删
除、新增子节点,例如上面 div 的子节点,把 p 和 span 顺序互换修改了节点的属性。对于文本
节点,文本内容可能会改变。
如果我把左侧的 p、span、div 反过来变成 div、p、span 怎么办?按照差异正常会被替换掉,
但这样 DOM开销就会异常的大了。而 React 帮我们做到不需要替换节点,而只需要经过节点移
动就可以达到。
深度优先遍历,记录差异
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历,这样每个节点都会有一个唯一的标记:
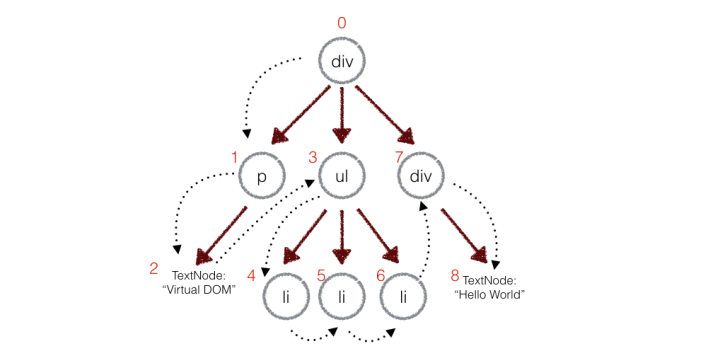
在深度优先遍历的时候,每遍历到一个节点就把该节点和新的的树进行对比。如果有差异的话就记录到一个对象里面。
// diff 函数,对比两棵树
function diff (oldTree, newTree) {
var index = 0 // 当前节点的标志
var patches = {} // 用来记录每个节点差异的对象
dfsWalk(oldTree, newTree, index, patches)
return patches
}
// 对两棵树进行深度优先遍历
function dfsWalk (oldNode, newNode, index, patches) {
// 对比oldNode和newNode的不同,记录下来
patches[index] = [...]
diffChildren(oldNode.children, newNode.children, index, patches)
}
// 遍历子节点
function diffChildren (oldChildren, newChildren, index, patches) {
var leftNode = null
var currentNodeIndex = index
oldChildren.forEach(function (child, i) {
var newChild = newChildren[i]
currentNodeIndex = (leftNode && leftNode.count) // 计算节点的标识
? currentNodeIndex + leftNode.count + 1
: currentNodeIndex + 1
dfsWalk(child, newChild, currentNodeIndex, patches) // 深度遍历子节点
leftNode = child
})
}例如,上面的div和新的div有差异,当前的标记是0,那么:
patches[0] = [{difference}, {difference}, ...] // 用数组存储新旧节点的不同同理p是patches[1],ul是patches[3],类推。
差异类型
上面说的节点的差异指的是什么呢?对 DOM 操作可能会:
- 替换掉原来的节点,例如把上面的div换成了section
- 移动、删除、新增子节点,例如上面div的子节点,把p和ul顺序互换
- 修改了节点的属性
- 对于文本节点,文本内容可能会改变。例如修改上面的文本节点2内容为Virtual DOM 2
所以我们定义了几种差异类型:
var REPLACE = 0
var REORDER = 1
var PROPS = 2
var TEXT = 3对于节点替换,很简单。判断新旧节点的tagName和是不是一样的,如果不一样的说明需要替换掉。如div换成section,就记录下:
patches[0] = [{
type: REPALCE,
node: newNode // el('section', props, children)
}]如果给div新增了属性id为container,就记录下:
patches[0] = [{
type: REPALCE,
node: newNode // el('section', props, children)
}, {
type: PROPS,
props: {
id: "container"
}
}]
那如果把我div的子节点重新排序呢?例如p, ul, div的顺序换成了div, p, ul。这个该怎么对比?如果按照同层级进行顺序对比的话,它们都会被替换掉。如p和div的tagName不同,p会被div所替代。最终,三个节点都会被替换,这样DOM开销就非常大。而实际上是不需要替换节点,而只需要经过节点移动就可以达到,我们只需知道怎么进行移动。
列表对比算法
假设现在可以英文字母唯一地标识每一个子节点:
旧的节点顺序:
a b c d e f g h i
现在对节点进行了删除、插入、移动的操作。新增j节点,删除e节点,移动h节点:
新的节点顺序:
a b c h d f g i j
现在知道了新旧的顺序,求最小的插入、删除操作(移动可以看成是删除和插入操作的结合)。这个问题抽象出来其实是字符串的最小编辑距离问题(Edition Distance),最常见的解决算法是 Levenshtein Distance,通过动态规划求解,时间复杂度为 O(M * N)。但是我们并不需要真的达到最小的操作,我们只需要优化一些比较常见的移动情况,牺牲一定DOM操作,让算法时间复杂度达到线性的(O(max(M, N))。具体算法细节比较多,这里不累述,有兴趣可以参考代码。
我们能够获取到某个父节点的子节点的操作,就可以记录下来:
patches[0] = [{
type: REORDER,
moves: [{remove or insert}, {remove or insert}, ...]
}]但是要注意的是,因为tagName是可重复的,不能用这个来进行对比。所以需要给子节点加上唯一标识key,列表对比的时候,使用key进行对比,这样才能复用老的 DOM 树上的节点。
这样,我们就可以通过深度优先遍历两棵树,每层的节点进行对比,记录下每个节点的差异了。
结语
实际还需要处理事件监听、状态监控。生成虚拟 DOM 时也可以加入 JSX 语法。当然这些事情都做了的话,就可以构造一个简单的ReactJS了。




